

Random Forest („zufälliger Wald“) ist eine Möglichkeit, mithilfe von Machine Learning Datensätze zu klassifizieren. In diesem Blogbeitrag erfährst du anhand eines Beispiels, wie ein einzelner Entscheidungsbaum aufgebaut ist, wozu du einen ganzen Wald brauchst und welche Vorteile dieses Verfahren im Vergleich zu anderen Machine-Learning-Verfahren bietet.
Machine Learning ist ein Teilbereich von Künstlicher Intelligenz und befasst sich mit dem künstlichen Lernen aus historischen Daten. In diesen Daten sollen Muster und Regelmäßigkeiten erkannt werden, um daraus Entscheidungsregeln abzuleiten. Wie das genau funktioniert, kann allerdings von Modell zu Modell stark variieren.
Strukturierung von Datensätzen mithilfe von Entscheidungsbäume
Grundlage eines Random Forests sind Entscheidungsbäume. Solch ein Baum besteht aus einer Verzweigung von einfachen Regeln. Diese teilen historische Datensätze anhand ihrer Eigenschaften in Klassen ein (siehe Abbildung 1). Welche Eigenschaften genau zum Treffen der Entscheidung genutzt werden, ist dabei zufällig bestimmt und daher von Baum zu Baum unterschiedlich.
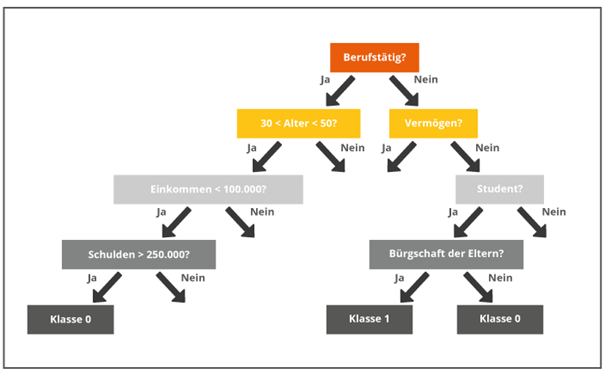
Abbildung 1: Beispiel eines Entscheidungsbaums
Abbildung 1 zeigt einen Baum, der die Kategorien einer Person erfasst. Hier ist der Ausgangspunkt die Berufstätigkeit. Je nachdem, ob die Eigenschaft zutrifft oder nicht, werden weitere Kategorien abgefragt und erneut entschieden, ob diese Eigenschaft zutrifft oder nicht (ja/nein). Zum Abschluss wird die Person dann einer Klasse zugeordnet.
Ziel eines einzelnen Baums ist nicht, alle Datensätze korrekt einer Klasse zuzuordnen. Stattdessen wird lediglich versucht, so viele Datensätze wie möglich auf Grundlage der ermittelten Eigenschaften zur Entscheidungsfindung korrekt zu klassifizieren.

Komplexe Probleme erfordern mehr – Der Aufbau eines Waldes
Ein einzelner Entscheidungsbaum stößt bei komplexeren Problemen schnell an seine Grenzen. Der Trick bei Random Forests besteht darin, nicht nur einen, sondern viele Entscheidungsbäume zu generieren. Jeder dieser Bäume nutzt eine andere Kombination und Reihenfolge von Entscheidungskriterien.
Bei neu zu klassifizierenden Daten wird jedem Baum derselbe Datensatz zugeführt. Welcher Klasse der Random Forest den neuen Datensatz zuordnet, hängt dann von den Einzelentscheidungen der Bäume ab. Im Grunde ist ein Random Forest daher ein Mehrheitsentscheid vieler einzelner Entscheidungsbäume.

Vorteile von Random Forests
Das Klassifizieren von Datensätzen mithilfe von Random Forests bietet einige Vorteile:
- Die Trainingszeit von Random Forests ist im Vergleich zu einigen anderen Machine-Learning-Verfahren sehr gering.
- Die Entscheidungen der einzelnen Bäume sind voneinander unabhängig. Das führt dazu, dass sich Random Forests sehr gut parallelisieren lassen.
- Im Gegensatz zu manch anderen Verfahren – wie vor allem neuronalen Netzen – lässt sich das Entscheidungsverhalten von Random Forests verhältnismäßig leicht untersuchen. So kannst du besser nachvollziehen, warum das KI-Modell bestimmte Entscheidungen trifft.
Fazit
Random Forests sind ein sehr nützliches Tool, um Machine Learning anzuwenden. Es ist jedoch bei weitem nicht die einzige Möglichkeit, um Entscheidungen auf der Grundlage von historischen Daten zu treffen. Du interessierst dich für Machine Learning und KI? Dann schau dir doch auch unsere anderen Beiträge zum Thema Künstliche Intelligenz an, wie beispielsweise den Beitrag „Wie funktioniert Deep Learning?“





